[toc]
アプリケーションログをRedshiftにロードしたいという案件があったので色々調べていたところ、AWS Lambda Based Amazon Redshift Database Loader というのがあったので使ってみました。
AWS Lambda Based Amazon Redshift Database Loader とは
(名称が長いので以降はRedshift Loaderと略します)
解説記事
Redshift Loader はAmazon謹製のツールで、S3にアップロードされたログなどのファイルをRedshiftへロードしてくれます。 Amazon Lambda, DynamoDB などマネージメントサービスだけで構成されているので管理の手間から開放してくれます。
Redshiftへデータをロードするツールは、Amazon Kinesis FirehoseやFluentdプラグイン(fluent-plugin-redshift)があります。また、自分でS3からRedshiftへデータロードするLambda Functionを作る方法もありますが、以下の点においてRedshift Loaderの方が優位性があります。
- Tokyoリージョンで使える
Amazon Kinesis Firehose は現時点(2016/09/02)でTokyoリージョンで使うことができませんが、Redshift Loaderなら使うサービスすべてTokyoリージョンで提供されているため使うことができます。
II. データロード失敗時へのリカバリが簡単にできる
fluent-plugin-redshift のデメリットの1つにRedshiftへデータロードが失敗した後にリカバリが面倒だということです。このプラグインの挙動としては S3にファイルアップロード後、COPYコマンドでRedshiftへデータロードしますが、ロードに失敗するとS3上にロードされないファイルが残ってしまいます。
Redshiftのクラスタにノードを追加、削除する場合、クラスタリサイズ中にはデータ投入ができなくなります(読み取りは可能)。 その状態で fluent-plugin-redshift のデータ投入が走ると、S3へファイルをアップロードするところまでは成功した上、その後の COPY の発行でエラーになるため、fluentdの処理は「S3へのアップロード処理から」リトライされます。 リトライされるので最終的には問題なく取り込まれるのですが、S3には投入できなかったファイルが残ったままになり、投入できたファイルとできなかったファイルには部分的に同一のログが重複して含まれる状態になります。 エラーになって取り込まれなかったファイルをきちんと消しておかないと、後日まとめて再取り込みをしようとしたときに、ログを重複して読み込んでしまうことになります。 Amazon SQSを利用してS3からRedshiftにデータ投入するRinというツールを書いた
ロード失敗した場合の挙動について実際に検証してみました。Redshiftのクラスターをリサイズして書き込みができない状態において挙動を確認しました。 リサイズは約20分間行われ、その間はRedshiftへ接続不可になったり、書き込みができなかったりしていたため、FluentdプラグインによってS3にアップロード後、Redshiftへのデータロードに失敗していました。 Redshiftへのデータロードに失敗するとFluentdによって何回かリトライがかかりますが、S3へのアップロードからリトライが開始されるため、以下のようにRedshiftへロードされないファイルがS3に残ってしまっていました。 アップロードしたいファイルが最終的にはRedshiftへ取り込まれるので問題は無いと言えるかもしれませんが、RedshiftとS3で差分があるのは何となくもやもやします。 「リサイズするときにデータロード止まればいいのでは」という考えもありますが、メンテナンスウインドウによってロードできない時間帯がどうしても生じてしまいますのでロード失敗後のリカバリについて考えなければなりません。
$ aws s3 ls s3://redshift-load-test/2016/09/08/18/
# Redshiftへデータロードされなかったファイル
2016-08-08 18:00:02 193 20160808-1800_00.gz
2016-08-08 18:05:33 193 20160808-1805_00.gz
2016-08-08 18:05:34 193 20160808-1805_01.gz
2016-08-08 18:05:36 193 20160808-1805_02.gz
2016-08-08 18:05:40 193 20160808-1805_03.gz
2016-08-08 18:05:48 193 20160808-1805_04.gz
2016-08-08 18:06:03 193 20160808-1806_00.gz
2016-08-08 18:07:38 193 20160808-1807_00.gz
2016-08-08 18:09:55 193 20160808-1809_00.gz
# Redshiftへデータロードされたファイル
2016-08-08 18:23:25 193 20160808-1823_00.gz
一方で、Redshift Loaderの場合はDynamoDBにバッチ単位でデータロードの結果が保存されているため、失敗した場合はコマンド1つで失敗したバッチのみ再実行することでリカバリが容易に行うことができます。
アーキテクチャ

(https://github.com/awslabs/aws-lambda-redshift-loader/blob/master/Architecture.png)
{kind=link}
仕組みは単純でS3にファイルがアップロードされると、それをフックにAWS Lambdaが実行されRedshiftへデータがロードされます。DynamoDBに設定値やロードするファイルリスト、ロードを実行するバッチの実行状況を格納することで管理をしています。
環境構築
Webサーバ、バッチサーバ、ログ集約サーバにFluentdを入れており、各サーバ(Web,バッチ)から集約サーバにログを送っています。 今回は集約サーバからS3にファイルをアップロードしたときに Redshift Loaderを使ってRedshiftへデータロードしてみました。 構成としては、以下の図のようにVPC内にLambda Function, Redshiftを作成し、Lambda Function は NAT Gatewayを経由してDynamoDBにアクセスするようにします。

(https://github.com/awslabs/aws-lambda-redshift-loader/blob/master/VPCConnectivity.png)
{kind=link}
VPC, NAT Gateway
Lambda Functionが実行できるプライベートサブネットを作成し、インターネットにアクセスできるようにNAT GatewayかNATインスタンスを作成します。ここでは設定方法は紹介しません。
S3
以下のようなS3バケットを作成します。バケットポリシーは適宜変更してください(デフォルトでも良い)。
| バケット | 用途 |
|---|---|
| redshift-loader | データロード用。このS3バケットに置いたファイルがRedshiftへロードされる |
| redshift-manifests | マニフェストファイルの保存用バケット |
Lambda
Configure triggers
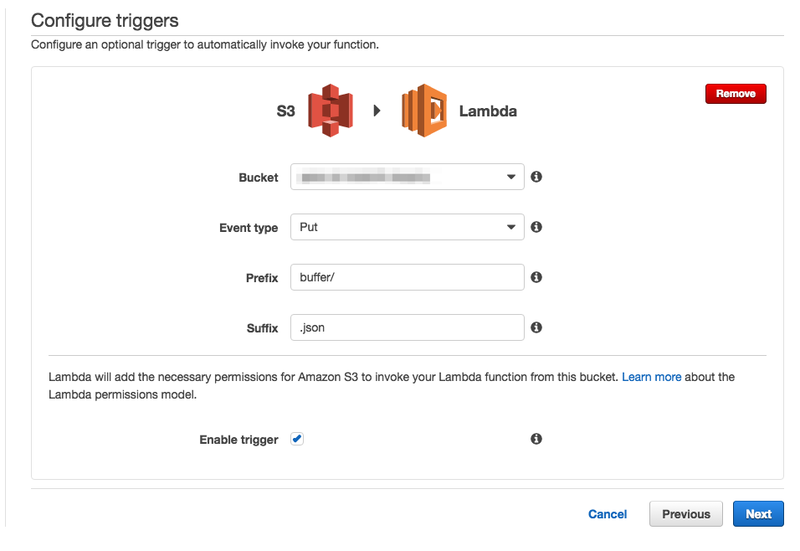
S3のイベントを追加します。
| 項目 | 備考 |
|---|---|
| Bucket | データロードするS3バケット(redshift-loader) |
| Event type | 後述 |
| Prefix | ログをアップロード先のパス。今回は buffer/ とする |
| Suffix | 拡張子(.json)を指定する |
Event typeについて以下の3つを設定します。
- ObjectCreatedByPut ・・・ ファイルがアップロードされた場合
- ObjectCreatedByCompleteMultipartUpload ・・・ マルチパートアップロードされた場合
- ObjectCreatedByCopy ・・・ ファイルがコピーされた場合。バッチ再起動する際にフックされる
Configure function
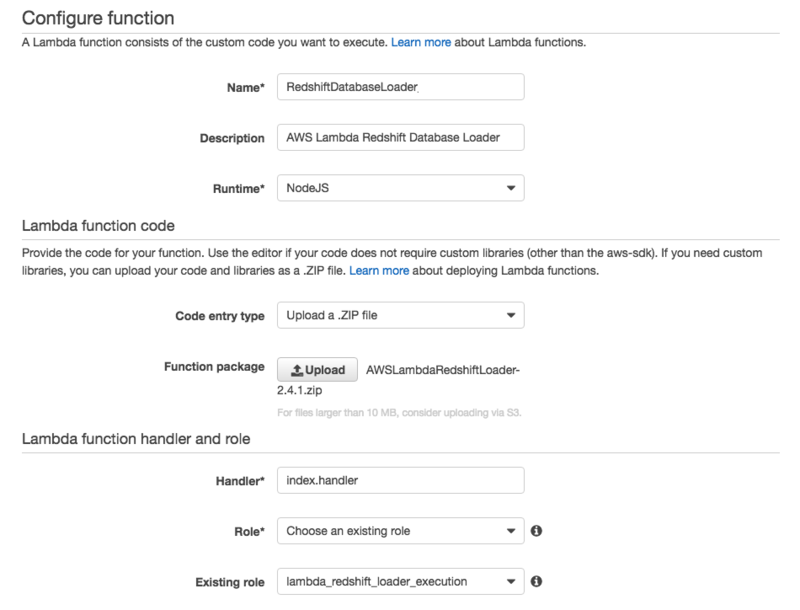
| 項目 | 備考 |
|---|---|
| Name | 今回はRedshiftDatabaseLoaderにした |
| Description | Lambda Functionの説明を入れる。後で変更も可能 |
| Runtime | README.mdによると Node.js v0.10 か v0.12 を指定する必要がある |
| Code entry type | 「Upload a .ZIP file」を選択 |
| Function package | AWSLambdaRedshiftLoader-2.4.1.zip をローカルにダウンロードしてアップロードする |
| Handler | デフォルト(index.handler)でOK |
| Role | 後述 |
Role

新規でRoleを作成します。ポリシーは以下のようにしました。 Redshift Loaderで必要なポリシーに加え、CloudWatch Logsへの記録とVPCエンドポイント化に必要なポリシーも追加しています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1424787824000",
"Effect": "Allow",
"Action": [
"dynamodb:DeleteItem",
"dynamodb:DescribeTable",
"dynamodb:GetItem",
"dynamodb:ListTables",
"dynamodb:PutItem",
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:UpdateItem",
"sns:GetEndpointAttributes",
"sns:GetSubscriptionAttributes",
"sns:GetTopicAttributes",
"sns:ListTopics",
"sns:Publish",
"sns:Subscribe",
"sns:Unsubscribe",
"s3:Get*",
"s3:Put*",
"s3:List*",
"kms:Decrypt",
"kms:DescribeKey",
"kms:GetKeyPolicy"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DeleteNetworkInterface"
],
"Resource": "*"
}
]
}
Advanced settings
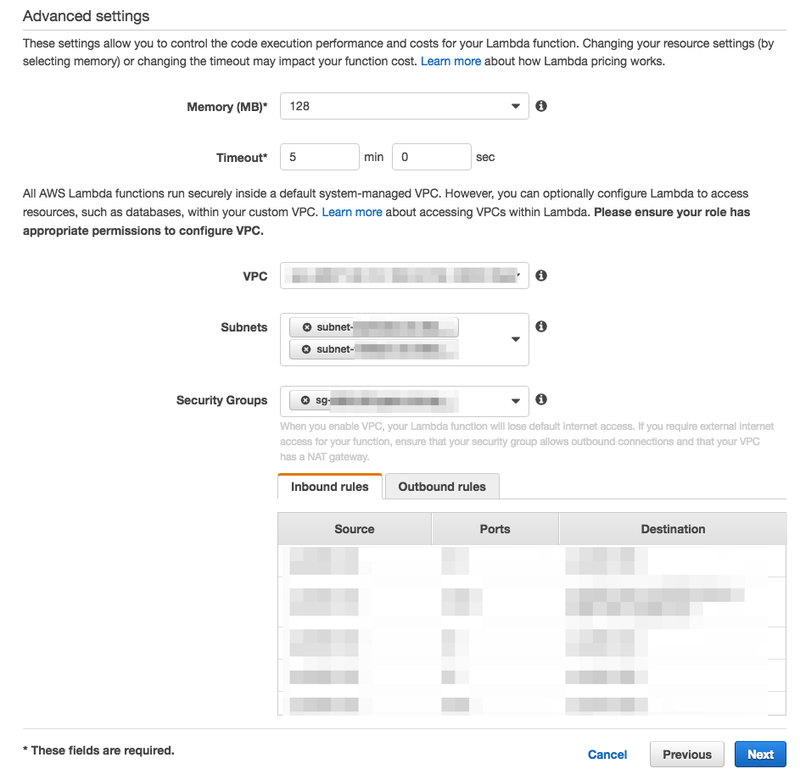
| 項目 | 備考 |
|---|---|
| Memory | とりあえず最小(128MB) |
| Timeout | 最大(5分間) |
| VPC | Lambda Functionを実行したいVPC |
| Subnet | Redshiftと5439ポートで通信ができる、S3, DynamoDBと通信できるサブネットを選択 |
| SecurityGroup | Redshiftと5439ポートで通信ができる、S3, DynamoDBと通信できるSecurityGroupを選択 |
Redshift
VPC内に構築します。Lambda FunctionからRedshiftに5439ポートでアクセスできるようにSecurityGroup, NetworkACLを設定してください。
クラスター名: test-redshift
IAM Role対応
次の記事を参考に設定しました。
[Amazon Redshift] RedshiftのIAM Roles利用が可能となりました。
IAM のマネジメントコンソールから先ほど作成したLambdaに関連づけられてロールを選択し、「Trust Relationships(信頼関係)」タブをクリックし、「Edit Trust Relationships(信頼関係の編集)」をクリック。 以下の信頼ポリシーに修正する。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"redshift.amazonaws.com",
"lambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
保存すると以下のように redshift.amazonaws.com が信頼関係に追加されればOK。

Amazon SNS
データロードの成功・失敗時にAmazon SNSに通知することができます。 作成したらTopic ARNをメモしておきます。
DynamoDB
セットアップする際に自動的に設定されるので何もしません。
Node.js
セットアップするために Node.js が動作する環境が必要です。 Lambda Functionで指定した時と同様に v0.10系かv0.12系で動作するようにします。
$ nvm ls-remote | grep "v0.12" | tail -n 1
v0.12.15
$ nvm install v0.12.15
$ nvm use v0.12.15
$ node --version
v0.12.15
AWS SDKの設定
$ npm install -g aws-sdk
リージョンを設定します。 プロファイルがあれば設定します。
$ export AWS_PROFILE=hoge
$ export AWS_REGION=ap-northeast-1
以上で環境構築は完了です。 次にセットアップします。
セットアップ
$ git clone https://github.com/awslabs/aws-lambda-redshift-loader.git
$ cd aws-lambda-redshift-loader
$ npm install
$ node setup.js
Enter the Region for the Configuration > ap-northeast-1
Enter the S3 Bucket & Prefix to watch for files > redshift-loader/buffer/web/
Enter a Filename Filter Regex >
Enter the Cluster Endpoint > test-redshift.xxxxxxxxxx.ap-northeast-1.redshift.amazonaws.com
Enter the Cluster Port > 5439
Does your cluster use SSL (Y/N) > N
Enter the Database Name > test_database
Enter the Table to be Loaded > test_table
Enter the comma-delimited column list (optional) >
Should the Table be Truncated before Load? (Y/N) > N
Enter the Database Username > test_user
Enter the Database Password > xxxxxxxxx
Enter the Data Format (CSV, JSON or AVRO) > JSON
Enter the JSON Paths File Location on S3 (or NULL for Auto) >
Enter the S3 Bucket for Redshift COPY Manifests > redshift-manifests
Enter the Prefix for Redshift COPY Manifests > manifests
Enter the Prefix to use for Failed Load Manifest Storage > failure
Enter the Access Key used by Redshift to get data from S3. If NULL then Lambda execution role credentials will be used >
Enter the Secret Key used by Redshift to get data from S3. If NULL then Lambda execution role credentials will be used >
Enter the SNS Topic ARN for Successful Loads >
Enter the SNS Topic ARN for Failed Loads > arn:aws:sns:ap-northeast-1:xxxxxxxxxxxxx:xxxxxxxxxxx
How many files should be buffered before loading? > 2
How old should we allow a Batch to be before loading (seconds)? > 3600
Additional Copy Options to be added > ACCEPTANYDATE TRUNCATECOLUMNS COMPUPDATE ON
If Encrypted Files are used, Enter the Symmetric Master Key Value >
Creating Tables in Dynamo DB if Required
Configuration for redshift-loader successfully written in ap-northeast-1
入力内容がたくさんあって大変ですが、Configuration Reference を見ながら設定していきます。(日本語訳もあります)。 途中で設定を間違えると最初からになるのが辛いです。。。
成功するとDynamoDBに以下のテーブルが作成されます。
| テーブル | 備考 |
|---|---|
| LambdaRedshiftBatches | バッチの実行状況 |
| LambdaRedshiftBatchLoadConfig | 各種設定(S3, Redshift) |
| LambdaRedshiftProcessedFiles | バッチ処理するファイルのリスト |
Fluentd側の設定
FluentdからS3にファイルをアップロードする設定を行います。 下記は設定ファイルから一部抜粋したものです。
<label @s3_redshift>
<match logger.**>
type forest
subtype s3
remove_prefix logger
<template>
s3_region ap-northeast-1
s3_bucket redshift-loader
path buffer/
time_slice_format %Y/%m/%d/%H
s3_object_key_format %{path}${tag}/%{time_slice}_%{index}.%{file_extension}
buffer_path /var/log/fluentd/buffer_redshift.${tag}.*.buffer
flush_interval 15m
buffer_chunk_limit 512m
format json
store_as json # Store as json at S3 (Default: gzip)
<instance_profile_credentials>
retries 5
</instance_profile_credentials>
</template>
</match>
</label>
buffer_chunk_limit は適当で良いですが、Lambda FunctionでRedshiftクラスターへデータロードできるサイズ/バッチサイズまでに留めておきます。
fluent-plugin-s3 ではデフォルトでGZIPに固めてアップロードされてしまいますが、Redshift Loader は生のJSONファイルでないとダメなので、JSONファイルでアップロードするようにしています。
実行結果の確認
S3にログを置くとLambda Function(RedshiftDatabaseLoader)が実行されます。
How many files should be buffered before loading?で指定したファイル数が置かれるとRedshiftへのデータロードが実行されます。
各バッチのステータスごとの一覧を取得する場合は以下のコマンドを実行します。
$ node queryBatches.js ap-northeast-1 complete | jq .
[
{
"s3Prefix": "redshift-loader/buffer/web",
"batchId": "325d8e81-d236-45b1-ae4d-43080cd92146",
"lastUpdateDate": "2016-07-07-15:51:04"
}
]
バッチの詳細を調べるには describeBatch.js を使います。
$ node describeBatch.js ap-northeast-1 325d8e81-d236-45b1-ae4d-43080cd92146 redshift-loader/buffer/web | jq .
{
"writeDates": {
"NS": [
"1467874262.352",
"1467874186.866"
]
},
"batchId": {
"S": "325d8e81-d236-45b1-ae4d-43080cd92146"
},
"manifestFile": {
"S": "redshift-manifest/manifests/manifest-2016-07-07-06:51:02-7123"
},
"entries": {
"SS": [
"redshift-loader/buffer/web/20160707-1549_0.json",
"redshift-loader/buffer/web/20160707-1550_0.json"
]
},
"s3Prefix": {
"S": "redshift-loader/buffer/web"
},
"lastUpdate": {
"N": "1467874264.646"
},
"clusterLoadStatus": {
"S": "{\"test-redshift.xxxxxxxxxx.ap-northeast-1.redshift.amazonaws.com\":{\"status\":0,\"error\":null}}"
},
"status": {
"S": "complete"
}
}
バッチの検索
S3のファイルパスを指定することでバッチIDなどを検索することができます。
node processedFiles.js ap-northeast-1 -q redshift-loader/buffer/web/20160707-1549_0.json | jq .
{
"loadFile": {
"S": "redshift-loader/buffer/web/20160707-1549_0.json"
},
"batchId": {
"S": "325d8e81-d236-45b1-ae4d-43080cd92146"
}
}
ファイルの削除
S3上のファイルを削除することができます。
$ node processedFiles.js ap-northeast-1 -d redshift-loader/buffer/web/20160707-1549_0.json
File Entry redshift-loader/buffer/web/20160707-1549_0.json deleted successfully
最後に
今回はAWS Lambda Based Amazon Redshift Database Loaderを使ってアプリケーションログをRedshiftへデータ投入してみたところまで紹介しました。 次回はデータロード時に失敗した場合のリカバリ方法などを紹介したいと思います。
このツールは良く出来ており、実際の運用でも使っていますが、Kinesis Firehoseが使えるようになればこのツールはお払い箱になるかもしれません・・・