AWSからGCPへの移行案件があったときに、EC2インスタンスからGCEインスタンスに移行する必要が出てくることがあります。
ChefやAnsibleなどでインフラ構成をコード化していたりクラウドベンダーロックされていなければ、新しいGCEインスタンスを作ってやればいいのですが、古くからあるインスタンスだとコード化されていないものも存在します。
そうしたインスタンスを移行するとなったらかなりの面倒になりそうですが、CloudEndure というツールを使うことでVM移行が簡単にできるようになります。
本記事はCloudEndureを使ってAmazon EC2からGCEへ移行する方法について紹介します。
- VM移行の全体像
- 移行対象サーバ
- AWS側の準備
- サービス アカウントとサービス アカウントキーを作成する
- CloudEndureへのサインイン
- CloudEndureプロジェクトの作成
- CloudEudureエージェントのインストール
- Blue Printの設定
- データが同期されるまで待つ
- テストモードでの検証
- カットオーバー
- GCEインスタンスで設定すること
- 参考
VM移行の全体像
CloudEndureを使ってどのようにEC2からGCEへの移行(VM移行, VMマイグレーション)を行うのかについては下図をご覧ください。
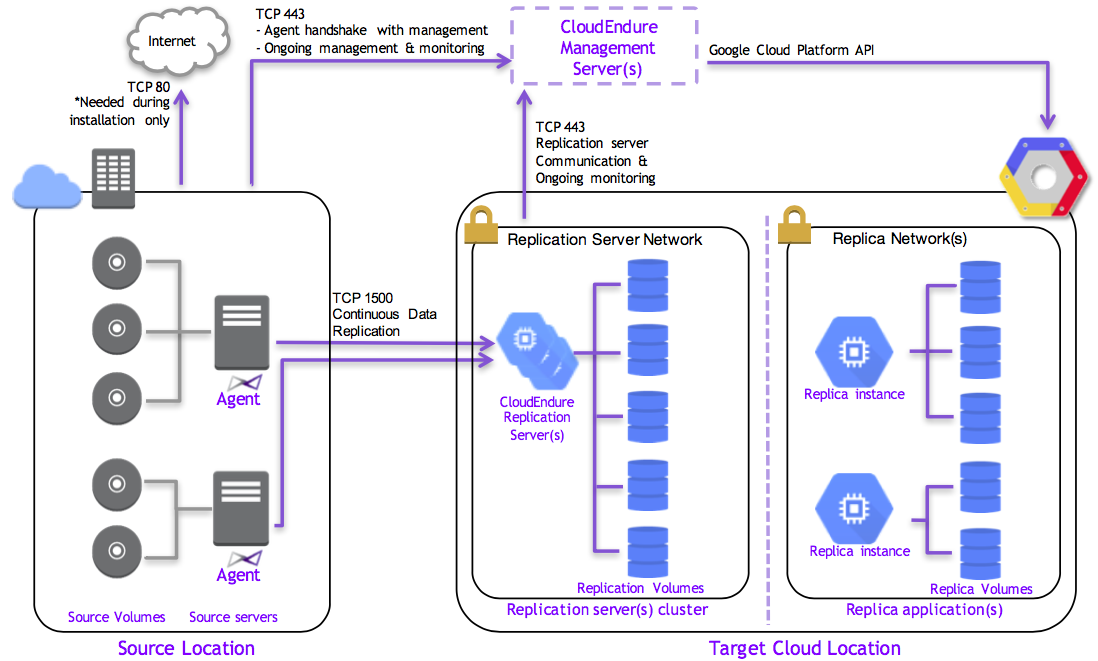
Source Location側にあるSource servers(移行元サーバ)にCloudEndureエージェントをインストールすることでエージェントは二つの通信が行います。
- VM移行やレプリケーションの監視などを行う
- 通信先: VM移行管理サーバ(
console.cloudendure.com) - TCP 443ポート
- 通信先: VM移行管理サーバ(
- 移行元にあるデータなどをコピー、レプリケーションする
- 通信先: レプリケーションサーバ
- TCP 1500ポート
- レプリケーション環境はCloudEndureによって、移行先GCPプロジェクトにおいてVPCネットワークやファイアウォール ルール *1、レプリケーションサーバとしてのGCEインスタンスが自動的に作成される
特徴として面白いのが、移行元サーバから直接データ移行するのではなく、レプリケーションサーバにデータ同期する点です。ほぼリアルタイムでデータ同期が反映されるため、計画次第ではダウンタイムを極力少なくすることができます。
移行対象サーバ
- Ubuntu Server 14.04 LTS *2
AWS側の準備
Security Group アウトバウンドルールの設定追加
CloudEndureエージェントが外部に通信できるように、TCP 443及び1500ポートをSecurity Groupのアウトバウンドルールに追加します。
移行元サーバの設定
できれば元のサーバのままで移行できればベストなのですが、GCEインスタンスにすることで動かなくなる箇所を直していきます。
諸事情で元のサーバに対して設定変更を加えられない場合は、AMIなどで移行元サーバを複製しそのサーバから移行した方がよいでしょう。
私が担当したEC2インスタンスでは以下の設定変更を行いました。
ここら辺をやっていないと、移行した後にGCEインスタンスが起動しなかったりSSH接続できない場合があります。
Active Directory(AD) or LDAP から離脱
AWS環境では AWS Directory Service でAD管理しているのですが、GCP環境ではADやLDAPを使っていないため抜けておきます。
また、PAMの設定も変更しているのであれば元に戻します。ADやLDAPの設定が残っているとSSH接続できない場合があります。今回はまっさらなEC2インスタンスのPAM設定ファイルをそのまま持ってきました。
パッケージアップデート(できれば)
できれば最新状態にしておくのがベストです。
追加EBSボリュームのアンマウント
追加ボリュームというのは、ルートボリューム(/dev/xvda1) 以外に /dev/xvdf などでアタッチしているEBSボリュームです。
EC2とGCEでマウントポイントが変わってしまい、GCEインスタンスだと起動できない場合があるため、予め umount コマンドでアンマウントしておきます。EBSボリュームがアタッチされている限りは CloudEndure によってボリュームごと移行されるため移行した後にGCEインスタンス内部で再度マウントすれば良いです。/etc/fstab も忘れずに追加ボリュームをコメントアウトしておきましょう。
サービス アカウントとサービス アカウントキーを作成する
ドキュメント を参考に、サービスアカウントキーのファイル(JSON)をダウンロードします。
CloudEndureへのサインイン
GCPのGCEインスタンス一覧に飛んで「VMのインポート」をクリックします。

CloudEndureをクリックし、Googleアカウントでサインインします。

CloudEndureプロジェクトの作成
プロジェクト名、GCPのプロジェクトID、移行先のゾーンを入力し、サービスアカウントJSONのファイルをアップロードします。

CloudEudureエージェントのインストール
下図のようにトークンとインストールコマンドが表示されるので、控えておきます。

先ほど控えたインストールコマンドを、移行元サーバ(EC2インスタンス)で実行します。
% wget -O ./installer_linux.py https://gcp.cloudendure.com/installer_linux.py % sudo python ./installer_linux.py -t <トークン> --no-prompt The installation of the CloudEndure Agent has started. Running the Agent Installer for a 64 bit system... Connecting to CloudEndure Console... Finished. Identifying disks for replication. Disk to replicate identified: /dev/xvda of size 10.0 GiB Disk to replicate identified: /dev/xvdf of size 500.0 GiB All disks for replication were successfully identified. Downloading CloudEndure Agent... Finished. Installing CloudEndure Agent... Finished. Adding the Source machine to CloudEndure Console... Finished. Instance ID: i-xxxxxxxxxxxxxxxxx. Installation finished successfully.
Blue Printの設定
レプリケーションサーバのマシンタイプを決定します。カスタムマシンタイプにできないので提供されているインスタンスタイプから選びます。
インスタンスタイプは何でも良いのですが、あまりにも小さいとレプリケーションの同期完了までに時間を要してしまうため、ある程度大きめで良いと思います。

データが同期されるまで待つ
下図のようにレプリケーションサーバが自動作成されます。データがすべて同期されるまでしばらく待ちます。
ディスク容量が大きいほど同期完了までに時間がかかるため、時間短縮したい場合は予めEBSボリュームを小さくするか、レプリケーションサーバのインスタンスタイプを大きくしておきます。今回500GBだったので一晩かかりました。

テストモードでの検証
Machines -> インスタンスを選択 -> 「LAUNCH TARGET MACHINE」から「Test Mode」をクリックするとテスト用のGCEサーバが起動されます。そのサーバでログインができるか、必要なプロセスが起動しているかを確認します。

カットオーバー
先程の上図から「CutOver」をクリックすると、移行した VM の最終コピーを最新の状態で起動されます。テストモードと同様にログインなどに問題がないことを確認します。
ダウンタイムを最小限に留めたいのであれば移行計画をきちんと練る必要があります。
GCEインスタンスで設定すること
これも各自の環境で必要に応じてやってほしいのですが、私の手元の環境では以下のことを行いました。
一つのディスクにまとめる
複数のボリュームがアタッチされているかつ、GCEのイメージ *3 を作成するときに必要な作業です。GCEの仕様上、複数ディスクをまとめてイメージにできないため、一つのディスクにまとめる必要があります。
まず、コンソール画面からルートディスクを拡張します。今回、拡張ボリュームが500GBだったため、10GB -> 500GB に変更しました。拡張は数分で完了します。
次にOS側の拡張とデータコピーします。
# OS側で拡張 % LANG=C growpart /dev/sda 1 % resize2fs /dev/sda1 # 追加ボリュームをマウント % mount /dev/sdb /mnt # データコピー # /export はデータコピー先 % cd /mnt % nohup tar zcvf /export/export.tar.gz ./ > /tmp/tar.log 2>&1 & % cd /export && tar zxf export.tar.gz
名前解決ができない問題の解消
VM移行の影響なのか、 /etc/resolv.conf が消えていました。resolvconfはファイルが消えると自動生成してくれないため以下のように対処しました。
# シンボリックリンクを張る % ln -s /run/resolvconf/resolv.conf /etc/resolv.conf # resovconfを再起動 % initctl restart resolvconf # ネットワーク再起動 % ifdown eth0 && ifup eth0
/etc/resolv.conf が作成されて名前解決できればOKです。
% cat /etc/resolv.conf # Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8) # DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN nameserver 169.254.169.254 search c.[PROJECT ID].internal google.internal % nslookup google.com Server: 169.254.169.254 Address: 169.254.169.254#53 Non-authoritative answer: Name: google.com Address: 172.217.161.78
時刻同期の設定変更
AWSから持ってきてままだと同期先が変わっていないので変更します。
--- /etc/chrony/chrony.conf.orig 2016-12-27 14:58:30.262766392 +0900 +++ /etc/chrony/chrony.conf 2018-08-24 19:27:47.457248979 +0900 @@ -17,8 +17,7 @@ # fails they will be discarded. Thus under some circumstances it is # better to use IP numbers than host names. -server 169.254.169.123 prefer iburst # Amazon Time Sync Service +server metadata.google.internal prefer iburst # Look here for the admin password needed for chronyc. The initial # password is generated by a random process at install time. You may
% service chrony restart % chronyc sources 210 Number of sources = 1 MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* metadata.google.internal 2 6 17 6 -3794ns[ -213us] +/- 414us % chronyc tracking Reference ID : 169.254.169.254 (metadata.google.internal) Stratum : 3 Ref time (UTC) : Fri Aug 24 10:29:09 2018 System time : 0.000016007 seconds fast of NTP time Last offset : -0.006317797 seconds RMS offset : 0.006317797 seconds Frequency : 12.960 ppm fast Residual freq : -98.321 ppm Skew : 4.020 ppm Root delay : 0.000844 seconds Root dispersion : 0.002075 seconds Update interval : 64.1 seconds Leap status : Normal
GCEインスタンスの起動を早くする
本来であればGCEインスタンスを作成して1分未満でSSH接続できるのですが、VM移行したGCEインスタンスだと5分ぐらいかかっていました。
説明を省きますが、システムログと設定を追っていった結果、以下の設定変更を行うと起動とSSH接続までにかかる時間が短縮されました。
--- /etc/network/interfaces.orig 2018-08-24 18:43:17.153359456 +0900 +++ /etc/network/interfaces 2018-08-24 18:49:38.936352074 +0900 @@ -5,10 +5,10 @@ iface eth0 inet dhcp # for gcp -auto ens4 -iface ens4 inet dhcp +#auto ens4 +#iface ens4 inet dhcp # for aws C5,M5 -auto ens5 -iface ens5 inet dhcp +#auto ens5 +#iface ens5 inet dhcp
--- /etc/init/failsafe.conf.orig 2014-04-12 06:54:15.000000000 +0900
+++ /etc/init/failsafe.conf 2018-08-24 17:24:33.341265857 +0900
@@ -29,10 +29,10 @@
# the end of this script to avoid letting the system spin forever
# waiting on it to start.
$PLYMOUTH message --text="Waiting for network configuration..." || :
- sleep 40
+ #sleep 40
$PLYMOUTH message --text="Waiting up to 60 more seconds for network configuration..." || :
- sleep 59
+ #sleep 59
$PLYMOUTH message --text="Booting system without full network configuration..." || :
# give user 1 second to see this message since plymouth will go
gcloudコマンドをインストール
入っているかと思いきや、なかったので手動でインストールしました。
% export CLOUD_SDK_REPO="cloud-sdk-$(lsb_release -c -s)" % echo "deb http://packages.cloud.google.com/apt $CLOUD_SDK_REPO main" | tee -a /etc/apt/sources.list.d/google-cloud-sdk.list % curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - % apt-get update && apt-get install google-cloud-sdk
AWS関連のエージェントを削除
Amazon SSM Agentを入れていたのですが、GCPで使わないので削除します。
% dpkg -r amazon-ssm-agent